L’objectif de ce cas d’utilisation est de faire le tour de toutes les possibilités pour traiter les données manquantes.
Pour pouvoir essayer les commandes ci-dessous, vous pouvez créer les données de test sur mockaroo.com :

Voici un apercu des données :

Technique de suppression
Cette approche consiste à supprimer les enregistrements contenant des valeurs manquantes.
Cette approche n’est pas recommandée, car elle peut entraîner une perte d’informations dans l’ensemble de données. Cependant, dans le cas où la proportion des données serait faible, cette approche peut être utilisée.

A) Suppression par liste (List wise deletion)
L’objectif va être de supprimer chaque enregistrement contenant des valeurs manquantes.
Pour cela, voici la commande a réaliser avec Pandas pour obtenir ce résultat :
df.dropna(subset=['Manpower'],how='any',inplace=True)
# Ou bien :
df = df[df.Manpower.notnull()]
B) Suppression par paire (Pair wise deletion)
À l’inverse de supprimer la ligne complète, l’objectif de cette approche est de ne pas prendre en considération les données manquantes :
Avec l’utilisation d’un DataFrame, voici la commande à utiliser :
#Réinitialisation de l'index du dataframe
df_reset = df.reset_index()
#Réccupérer l'emplacement des données manquantes
df_index = df_reset.loc[df_reset.isnull().sum(1)>0].index
df = df.drop(df.index[df_index])
#Supprimer les lignes qui contiennent des valeurs manquantes
listwise_X_train = X_train.dropna()
C) Suppression par colonne
Ce type d’approche est très rarement utilisé, car elle peut parfois faire perdre énormément d’informations de nos données. Voici la ligne de commande :
df.dropna(axis = 1)
Technique d’imputations
On distingue 2 types d’approches pour imputer les données manquantes qui sont : 1) L’approche générale 2) L’approche avancée
A) Approche générale
Dans cette approche, on applique ces techniques à 2 types de données qui sont : 1) Des séries temporelles 2) Des séries non-temporelles
Nous allons d’abord nous pencher sur les séries non-temporelles.
1) Série non-temporelle
Pour les séries temporelles, nous pouvons remplacer les données manquantes par une constante.
Par exemple, si l’on reprend notre précédent tableau, nous pouvons appliquer cette ligne de commande pour remplacer les valeurs manquantes par des 0 :
df = df[df.isna()] = 0
Ou bien en utilisant sklearn pour appliquer une méthode de transformation sur nos données comme ceci :
from sklearn.impute import SimpleImputer
df_constant = df.copy()
mean_imputer = SimpleImputer(strategy='constant')
df_constant.iloc[:,:] = mean_imputer.fit_transform(df_constant)
D’accord Mohamed… Mais comment appliquer des règles sur les données que l’on souhaite remplacer ?
Pas de panique, j’y viens :)
Pour remplacer les données par la valeur la plus fréquente de la colonne, voici la commande à appliquer :
from sklearn.impute import SimpleImputer
df_most_frequent = df.copy()
mean_imputer = SimpleImputer(strategy='most_frequent')
df_most_frequent.iloc[:,:] = mean_imputer.fit_transform(df_most_frequent)
2) Série temporelle
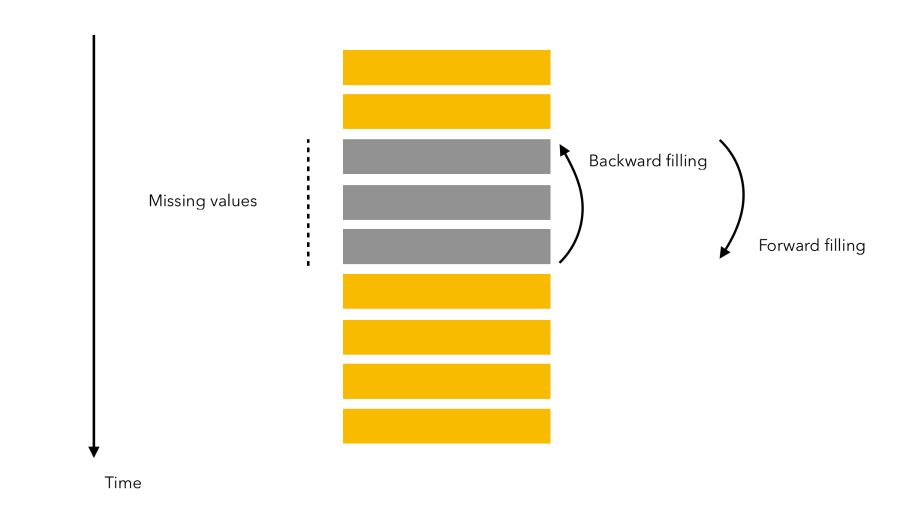
Il est possible de remplacer les valeurs de série temporelle de trois manières différentes qui sont : 1) Remplissage avant (Forward Fill) 2) Remplissage arrière (Backward Fill) 3) Interpolation linéaire (Linear Interpolation)
Le remplissage avant et le remplissage arrière sont deux approches pour remplir les valeurs manquantes.
Le remplissage avant signifie que l’on remplit les valeurs manquantes avec les données précédentes. Le remplissage à rebours consiste à remplir les valeurs manquantes avec le point de données suivant.
L’interpolation linéaire est l’une des méthodes pour estimer la valeur prise par une fonction continue entre deux points déterminés (interpolation).

1) Remplissage avant (Forward Fill)
df.fillna(method='ffill',inplace=True)
2) Remplissage arrière (Backward Fill)
df.fillna(method='bfill',inplace=True)
3) Interpolation linéaire (Linear Interpolation)
df.interpolate(limit_direction="both",inplace=True)
D’accord, mais les données ajoutées ne reflètent pas l’attribut (colonne) … :/
Effectivement. Dans l’approche précédente, nous remplacions les données en fonction des données du Datasets dans sa globalité. Maintenant, nous allons essayer d’aller un peu plus loin.
A) Approche avancée
Dans cette catégorie, on retrouve des techniques d’imputation avancées qui utilisent des algorithmes d’apprentissage automatique pour imputer les valeurs manquantes dans un ensemble de données.
Voici les deux techniques : 1) Imputation par les plus proches voisins (KNN) 2) Imputation de caractéristiques multivariées (MICE)
1) KNN
from sklearn.impute import KNNImputer
train_knn = df.copy(deep=True)
knn_imputer = KNNImputer(n_neighbors=2, weights="uniform")
train_knn['Manpower'] = knn_imputer.fit_transform(train_knn[['Manpower']])
2) MICE
from sklearn.experimental import enable_iterative_imputer
from sklearn.impute import IterativeImputer
train_mice = train.copy(deep=True)
mice_imputer = IterativeImputer()
train_mice['Manpower'] = mice_imputer.fit_transform(train_mice[['Manpower']])
Voilà :) nous avons fait le tour des techniques utilisées pour travailler avec des données manquantes
Sources
https://discuss.analyticsvidhya.com/t/how-can-we-treat-missing-datas-in-pandas-dataframe-through-deletion-in-python/1109/2
https://www.geeksforgeeks.org/drop-rows-from-pandas-dataframe-with-missing-values-or-nan-in-columns/
https://www.kaggle.com/parulpandey/a-guide-to-handling-missing-values-in-python
https://datascience.stackexchange.com/questions/57776/explain-forward-filling-and-backward-filling-data-filling