L’objectif de ce post va être de poser les bases de l’écosystème Hadoop afin d’avoir une vision claire des briques que contient la plateforme Hadoop.
Afin de comprendre ces briques, nous allons poser une définition simple et clair de ce que représente Hadoop.
Qu’est-ce qu’Hadoop ?
Hadoop est une plateforme destiné à créer des applications leur permettant d’effectuer des traitements de manière distribué. C’est un Framework open source écrit en Java et conçu selon une hypothèse que les pannes matérielles sont fréquentes et qu’elle doivent être gérer de manière automatique.
De quoi est composé ce Framework ?
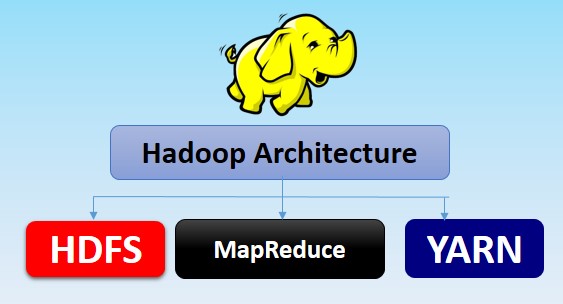
Hadoop contient trois modules principaux qui sont :
- HDFS
- MapReduce
- YARN
1) HDFS (Storage)
C’est un système de fichier qui est scalable et qui permet d’ajouter facilement des noeuds et des serveurs.
Il propose une solution de redondance des données afin de réduire le risque de perte de données. Les données sont ainsi dupliquées en 3 exemplaires et reparties sur 3 nœuds différents.
HDFS permet de résoudre les problèmes des précédents systèmes de gestion qui ne pouvaient pas prendre en charge les flux de données et les analyses en temps réel.
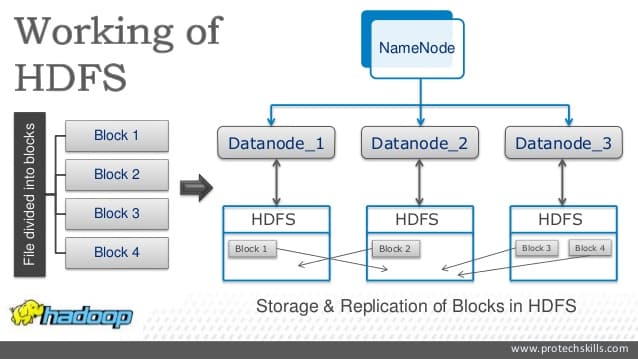
Le NameNode est le manager du cluster (serveur principal). Lorsque un client se connecte à l’HDFS, le système demande alors le NameNode. Il répond et indique les emplacements des blocks composant le fichier recherché par le client.
Les DataNodes se chargent de gérer le stockage associé aux nœuds. Ils permettent ou non, en fonction des instructions du NameNode, l’écriture ou la lecture des fichiers par le client.
Ils notifient régulièrement le NameNode en lui transmettant un “HeartBeat” qui assure le fonctionnement du DataNode et un “BlockReport” pour stocker la liste des blocs présents dans le DataNode.
DataNodes choisis retournent ensuite les données au client. Une fois le retour des données terminé, la connexion avec le client est fermée.
D’accord Mohamed, mais techniquement parlant comment configurer HDFS?
Le fichier core-site.xml indique l’host et le port du système de fichier HDFS :
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://master.local:9000</value>
<description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation.</description>
</property>
</configuration>
Le fichier hdfs-site.xml contient la configuration du NameNode et des DataNodes avec notamment l’emplacement du stockage de l’historique des transactions et des blocks. On y définit aussi le coefficient de réplication :
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
<description>The actual number of replications can be specified when the file is created.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/srv/hadoop/datanode</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>/srv/hadoop/namenode</value>
</property>
</configuration>
Voici les instructions permettant respectivement de formater le système de fichiers, de démarrer les daemons et notre NameNode et des DataNodes ainsi que de vérifier le bon fonctionnement en effectuant un ls du repértoire courant.
$HADOOP_PREFIX/bin/hdfs namenode -format
$HADOOP_PREFIX/sbin/start-all.sh
hdfs dfs -ls .
2) MapReduce (Processing)
C’est un concept d’architecture de programmation créé par Google. Aujourd’hui, ce concept est devenu un Framework central dans l’écosystème Hadoop. Il permet de manipuler de grandes quantités de données en les distribuant dans un cluster de machines pour être traitées.

MapReduce se compose de deux fonctions principales qui sont Map() et Reduce().
La première consiste à analyser un traitement et le découper en sous-traitement afin de déléguer chaque problème à chaque nœud du cluster.
La seconde fonction consiste à remonter et regrouper chaque résultat afin d’obtenir un résultat final.
3) YARN (Ressource Management)
Cette technologie permet d’allouer des ressources du système aux différentes applications exécutées dans un cluster.
Il offre la possibilité de lancer des applications en temps réel, de réaliser des requêtes interactives sur Apache Spark en utilisant en parallèle les fonctionnalisés fournit par MapReduce.
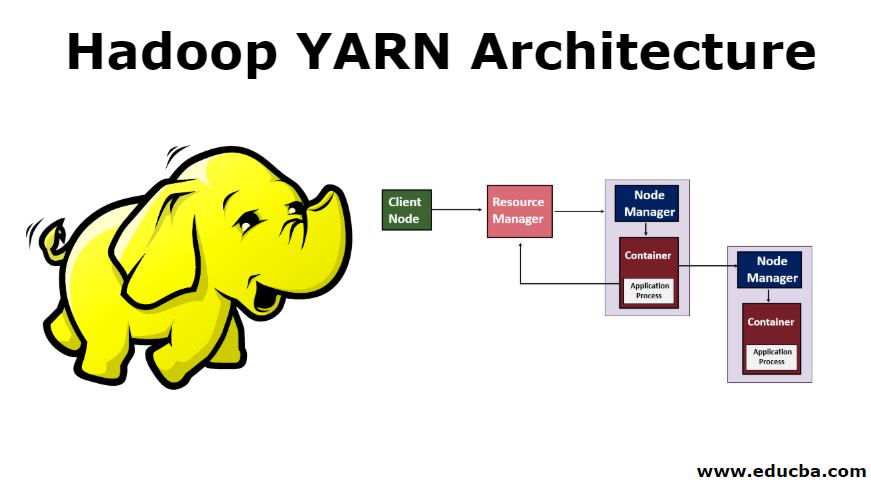
On retrouve plusieurs composants dans cette technologie qui sont :
- le gestionnaire de ressources (RessourceManager) permettant de gérer les tâches soumises par les utilisateurs en planifiant les tâches et en leur allouant les ressources suffisantes.
- le NodeManager et l’ApplicationMaster aide le RessourceManager en surveillant le bon déroulement des tâches. Une ApplicationMaster est unique et associé à une seul application.
- le containers de ressources permet quant à lui, d’assigner les ressources allouées aux applications.
Cet écosystème se compose du plusieurs logicielles permettant sa gestion en matières ingestion, de transformation et d’exposition.
En voici la liste :
A) Apache Spark B) Apache Kafka C) Sqoop D) Flume E) HBASE F) Hive G) Pig H) Oozie I) Zookeeper
Nous allons étudier le rôle de chaque solution afin d’évoquer les différents concepts de cet écosystème.
Les composants de l’écosystème
A) Apache Spark
Spark est un moteur de traitement de données qui permet d’effectuer un traitement de larges volumes de données de manière distribuée.
À l’inverse de MapReduce de Hadoop, travaillant étape par étape, Spark offre la possibilité de travaillé sur la totalité des données en même temps. Cela permet ainsi de gagner en rapidité dans les traitements de données qui peuvent parfois être non négligeable.
Ce Framework contient plusieurs composants :

1) Spark SQL permet simplement d’exécuter des requêtes SQL sur les données du cluster.
2) Spark Streaming est utilisé pour effectuer des traitements de données en temps-rêel.
3) Spark Graph X est un nouveau composant de Spark. Il permet de réaliser des calculs issus de la théorie des graphes. Ces calculs sont réalisés sur un ensemble de données appelé RDD (ensemble de données distribués et résilients) que l’on peut imager comme étant un graphe.
B) Apache Kafka
C’est un agent de message (message broker), codé en Scala et Java, permettant de manipuler des données en temps réel.
C’est un système de stockage de flux de messages (streams of records).
Un message est composé d’une valeur et d’une clé ainsi qu’un timestamp.
Kafka gère les messages en catégories appelé topics :
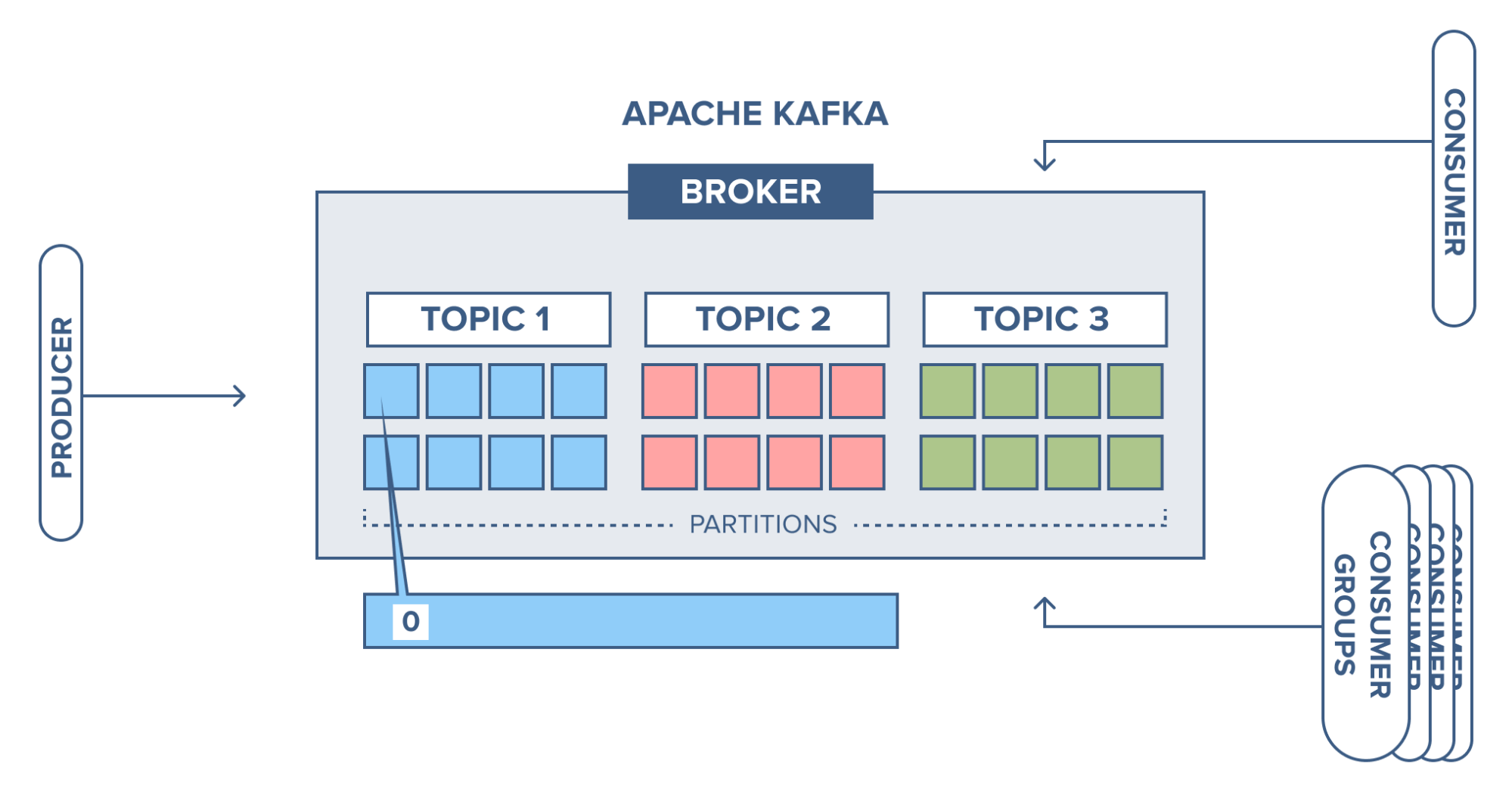 Chaque émetteur (client Kafka) peut seulement ajouter un message dans un topic à la fin de la pile (seulement).
Chaque émetteur (client Kafka) peut seulement ajouter un message dans un topic à la fin de la pile (seulement).

Le consommateur lit des topics à partir d’un index ou d’un timestamp donné, toujours dans l’ordre, c’est-à-dire du plus ancien message au plus récent, et sans s’arrêter.
Si un consommateur a traité tous les messages d’un topic, il y reste connecté pour recevoir les nouveaux messages insérés par les émetteurs.
Les topics sont immuable et peuvent être lus simultanément par de multiples consommateurs.
C) Sqoop
Sqoop joue un rôle vital dans l’écosystème Hadoop. Il offre un Shell permettant aux utilisateurs de Hadoop, d’importer des données depuis les bases de données relationnelles (MySQL, Oracle RDB, etc.) vers des couches de stockage (HDFS, HBase ou Hive). Sqoop veut dire “ SQL vers Hadoop”.
Voici le fonctionnement interne de Sqoop :

Sur HDFS, chaque ligne d’une table est considérée comme un enregistrement. La tâche principale qui est d’importer une table sera divisée en plusieurs tâches. Elles seront réalisées par un job Sqoop (Map) qui auront pour objectif d’importer une partie des données.

L’exportation utilise le même cheminement, mais à l’inverse de l’importation.
D) Flume
C’est un logiciel permettant la collecte, l’agrégation et le transfert de gros volumes de logs dont l’objectif est de gérer des pics de charge importante. Il est l’alternative à Kafka même si ce dernier répond à d’autres problématiques (message broker).

E) HBASE
C’est une base de données non-relationnelles, distribué, exécutée sur HDFS et conçue pour donner un accès en temps réel à des grandes tables. Il a été conçu sur le modèle de Google Bigtable.
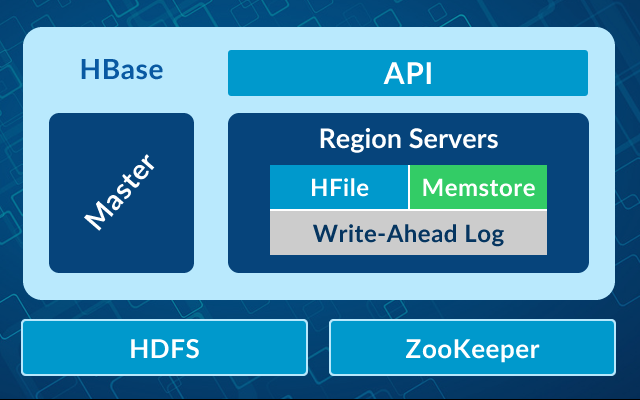
Les tables HBASE sont des collections de lignes de manière logique qui sont stockées dans différentes partitions appelées régions.
Les HBASE Rows représentent un enregistrement de données. Chaque enregistrement sont associé à une RowKey.
RowKey est utilisé pour identifier chaque entrée dans la table HBase
Write-Ahead Log (WAL) est un journal qui enregistre toutes les modifications apportés aux données dans HBase.
HFile est le format de fichier de paires clé/valeur triées de Hbase
Apache Phoenix offre la possibilité d’avoir un accès aux tables HBase avec le langage SQL.
Le MemStore est un tampon d’écriture où HBase accumule les données en mémoire avant une écriture permanente.
HMaster qui est responsable de la coordination des régions du cluster et de l’exécution des opérations administratives
F) Hive
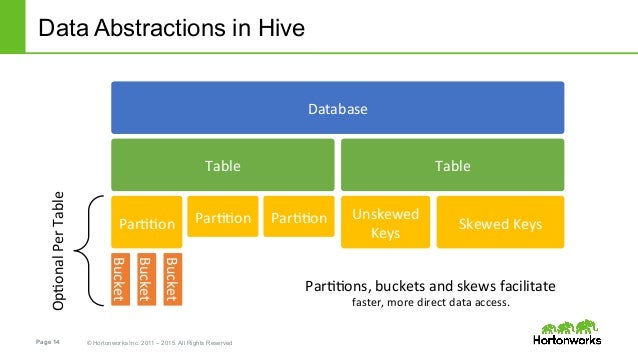
Hive est un entrepôt de données central où l’information provient d’une ou plusieurs sources de données. Il permet le requêtage des tableaux stocker dans HDFS avec un langage proche du SQL qui est le HiveQL (HQL).
Les bases de données Hive sont similaires aux bases de données relationnelles. Elles sont constituées de tableaux, composés de partitions. Les partitions peuvent être décomposées en “buckets”
G) Pig
C’est une solution logicielle codée en Java permettant l’écriture de scripts qui sont exécutés sur l’infrastructure Hadoop sans être obligé de passer par l’écriture de tâche via le framework MapReduce.
Il possède son propre langage qui est le Pig Latin. Il est souvent utilisé pour charger des données externes vers des fichiers HDFS.
H) Oozie
C’est un système de planification qui permet d’exécuter et de gérer des tâches Hadoop dans un environnement distribué.
Il permet de combiner plusieurs tâches complexes dans un ordre séquentiel pour accomplir une tâche plus importante.
On le considère comme un planificateur de workflow qui permet de donner des tâches d’importation envers le HDFS. Il offre également la possibilité de notifier le HDFS en termes de fichiers importés et exportés.
I) Zookeeper
C’est une solution distribué suivant l’architecture client-serveur. Elle permet la synchronisation et la coordination des systèmes distribués présent sur un cluster Hadoop.

Un Ensemble correspond à tous les nœuds de serveur de l’écosystème Zookeeper. Il en faut au moins 3 pour former un écosystème Zookeeper.
Un Server est l’un des serveur de l’écosystème et a pour objectif de fournir tous les services à ses clients.
Un Server Leader est élu au démarrage du service et est responsable de la récupération automatique des données pour les clients. Il a accès aux données des nœuds qui serait défaillants.
Un Server Follower suit les instructions passées par le Server Leader.
Un Client un nœud qui demande un service au serveur auquel il est associé. Il envoie un signal au serveur pour lui informer de sa disponibilité. Si le serveur ne répond pas, le nœud client se rédigera automatiquement vers le prochain serveur.
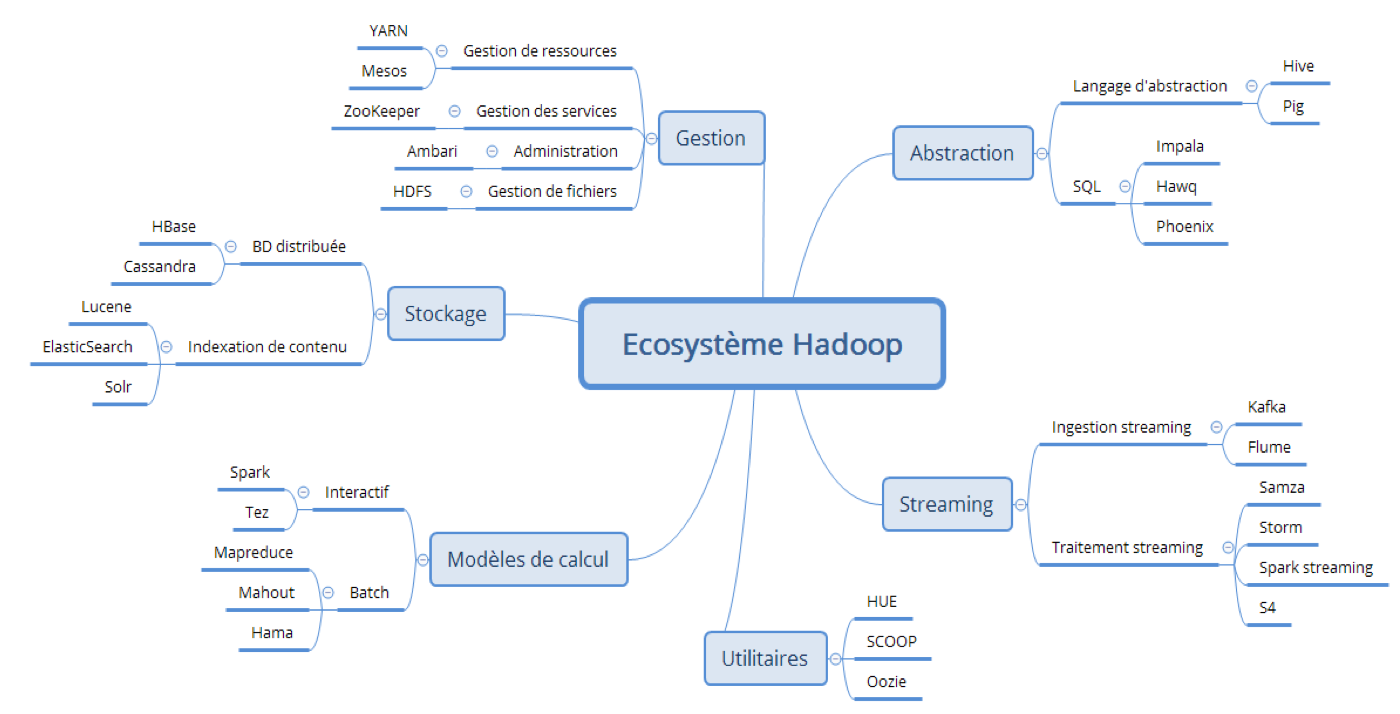
Il existe de nouvelles technologies dans l’écosystème Hadoop qui n’a pas été évoqué dans ce document et que vous pouvez retrouver sur ce schéma :
Sources
https://amitray.com/hadoop-architecture-in-big-data-yarn-hdfs-and-mapreduce/
https://amitray.com/hadoop-architecture-in-big-data-yarn-hdfs-and-mapreduce/
https://www.lebigdata.fr/hdfs-fonctionnement-avantages
https://stph.scenari-community.org/contribs/nos/Hadoop2/co/Comprendre_HDFS_2.html
https://www.lebigdata.fr/yarn-apache-hadoop
https://www.educba.com/hadoop-yarn-architecture/
https://livebook.manning.com/book/spark-graphx-in-action/chapter-4/
https://fr.wikipedia.org/wiki/Objet_immuable
https://blog.zenika.com/2017/09/14/mais-cest-quoi-apache-kafka/
https://www.talend.com/fr/resources/sqoop/
https://data-flair.training/blogs/sqoop-architecture-and-working/
https://blog.octo.com/introduction-a-flume-ng/
https://java2blog.com/hadoop-hbase/
https://datascientest.com/apache-hive
https://www.lebigdata.fr/apache-zookeeper-tout-savoir-sur-le-systeme-de-coordination